bubbled
-
Posts
93 -
Joined
-
Last visited
-
Days Won
2
Recent Profile Visitors
8131 profile views

bubbled's Achievements
")





-
I think have the answer to the second part:
-
Is it OK assume exactly 4 busses per hour, but arriving at completely random times? I can simulate that. Clearly, if the city had the busses arrive at exactly 15 minute intervals, then wait times would average around 7.5 minutes. And no one would ever wait longer than 15 minutes.
-
I think I figured out the first question:
-
Agree with Ed on first part. Can you clarify the second question?
-
Hmm: Hmm: Hidden Content Re-ran the script with a couple of changes:
-
Here are my results:
-
Cutting a circle to find a point part two
bubbled replied to BMAD's question in New Logic/Math Puzzles
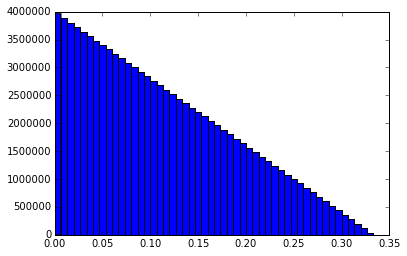
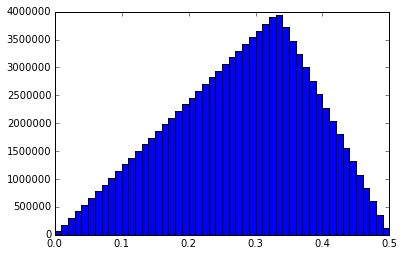
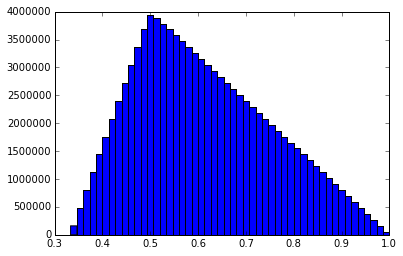
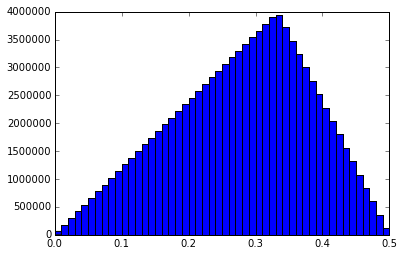
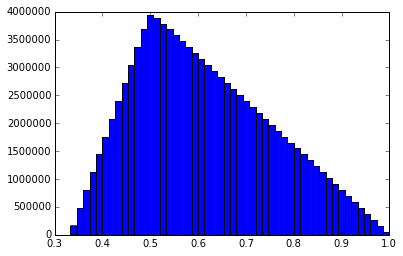
I just ran one more 100M simulation and captured a lot more info. Probability that a new random point will fall in the largest arc: 0.61104318 Mean of the arc length that captures the random point: 0.499978733972 Mean of the sums of the squared arc lengths: 0.500018084204 Median length of the longest arc: 0.591768881555 Histogram of the shortest arc lengths: Histogram of the middle arc lengths: Histogram of the longest arc lengths: I might be the only one, but I find these graphs to be interesting. Anytime you have two or more random variables and are trying to say things about their relationships to each other, things get pretty non-intuitive.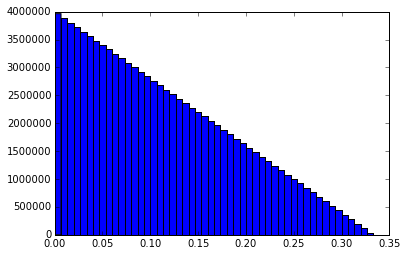
-
Cutting a circle to find a point part two
bubbled replied to BMAD's question in New Logic/Math Puzzles
I think it's interesting that the sum of the squares of the means doesn't match the mean of the sum of the squares. Maybe that shouldn't be interesting? -
Cutting a circle to find a point part two
bubbled replied to BMAD's question in New Logic/Math Puzzles
OK, so I continued by using bonanova's idea of picking the arcs and then spinning the wheel. I used the same method as above (picking two random points) and creating three arcs. I then pick a random new point and find the length of the arc it falls in. I store those lengths in a separate array and find the mean length. With 100,000,000 million trials, I get 0.500034371498. This it what we'd expect. But I'm confused as to why the sum of the squares doesn't add up to .5 as well. It must be something to do with the distribution of the actual lengths of the arcs. Maybe because when the longest arc is bigger than the mean of the other longest arcs, the random point will fall in it more often? More simulations necessary to answer that question. -
Cutting a circle to find a point part two
bubbled replied to BMAD's question in New Logic/Math Puzzles
I ran a simulation of 100,000,000 trials using bonanova's method (I think) on a unit circumference. I pick two random numbers, P1 and P2, between 0 and 1. If P1 < P2, then my three lengths are L1 = P1, L2 = P2 - P1, and L3 = 1 - P2. If P2 < P1, L1 = P2, L2 = P1 - P2, and L3 = 1 - P1. I sort the three lengths and put them into a matrix where the first column consists of all the shortest lengths, the second column is the middle length and the third column is the longest length. I then calculate the mean of the various columns. I get this result: mean of longest arcs = 0.611101750112 mean of middle arcs = 0.277769774084 mean of shortest arcs = 0.111128475804 This matches bonanova's results pretty closely and those lengths add up to 1, as expected. It would seem to me that the probability that a particular point falls in the longest arc should be 0.6111... And the middle arc 0.277... and shortest arc 0111... Which means that the average length of the arc that a random point (or fixed point) falls in should be the sum of the squares of the mean arc lengths. However, the sum of the squares is only 0.462950934519. I would expect it to be .5, given the analysis from the previous problem. I'm a bit confused. Thoughts? -
Hidden Content Hidden Content Hidden Content Expanding on my post of Sunday at 8:09 AM: Hidden Content I can't disagree with any of this. I was completely wrong and the fact that my answer matched with the correct answer blinded me to the fact that I was introducing an extra point into the problem. I now realize that you have to be very careful with how exactly you apply random conditions to problems like these.
-
-
but then I realize it was not working. I've tested it using dev-C++. the chance to find your name is only 50%, the same chance with random way opening boxes. in my program : box numbered from 0 to 9, and your number is random from 0 to 9. You can only open 5 boxes to find your name. Yes, it does work:
-
At a track meet, you have 25 runners for a 100 meter event and only 5 lanes. You've forgotten all of your timing devices at home. Assume that all runners {R1, R2,...R25} run the event in different times from each other, but an individual runner RN, will run the event in the same time each time he/she runs. Your job is to figure out who is the 1st, 2nd and 3rd fastest runners. What is the minimum number of heats needed to make your determination?
-
I was close to answering, but didn't understand my result yet: